- Home
- Leistungen
- Sichere Digitalisierung
- KI-Sicherheit
- Home
- Leistungen
- Sichere Digitalisierung
- KI-Sicherheit

AI Assurance | Sichere und vertrauenswürdige KI
Der Einsatz von Künstlicher Intelligenz (KI) ist immer auch eine Entscheidung über Risiken, Verantwortung und langfristige Auswirkungen.
Künstliche Intelligenz eröffnet neue Möglichkeiten, Prozesse effizienter, schneller und autonomer zu gestalten. Gleichzeitig entstehen neue Herausforderungen: Organisationen müssen fundiert beurteilen können, ob und unter welchen Bedingungen ein KI-System sicher, nachvollziehbar und verantwortbar eingesetzt werden kann.
Gerade in sicherheitskritischen und regulierten Kontexten reichen klassische Bewertungsansätze dafür häufig nicht aus. Risiken entstehen oft nicht im Modell selbst, sondern erst im realen Einsatz – etwa durch veränderte Umweltbedingungen, unvollständige Eingangsdaten oder operative Einschränkungen. Bereits kleine Abweichungen von den erwarteten Einsatzbedingungen können das Verhalten eines Systems beeinflussen.
Zugleich steigen die Anforderungen an Sicherheit, Transparenz, Nachweisbarkeit und regulatorische Konformität. Organisationen stehen damit vor der Herausforderung, KI-Systeme nicht nur technisch zu bewerten, sondern ihre Vertrauenswürdigkeit und Einsatzfähigkeit belastbar nachzuweisen – heute und unter zukünftigen Anforderungen.
Was Organisationen jetzt benötigen
Organisationen benötigen belastbare Aussagen darüber, ob ein KI-System vertrauenswürdig und zukunftssicher ist, unter welchen Bedingungen es eingesetzt werden kann und wie mit Unsicherheiten, Fehlern oder Veränderungen im Betrieb umzugehen ist.
Viele Organisationen adressieren diese Fragen bislang über isolierte Maßnahmen wie klassische Software-Tests, Checklisten oder Einzelbewertungen. Diese Ansätze liefern wichtige Bausteine, greifen jedoch häufig zu kurz, um reale Risiken im Betrieb zuverlässig zu bewerten.
Ein fundierter AI-Assurance-Ansatz muss deshalb zentrale Fragen beantworten:
- Nach welchen technischen, regulatorischen und ethischen Anforderungen muss ein KI-System bewertet werden?
- Welche konkreten Kriterien ergeben sich daraus für Robustheit, Nachvollziehbarkeit und Sicherheit?
- Wie lassen sich Prüfung, Nachweisführung und Monitoring verlässlich und effizient umsetzen?
AI Assurance − unser Ansatz
AI Assurance ist ein strukturierter Ansatz zur Bewertung, Absicherung und Nachweisführung von KI-Systemen im realen Einsatz. Sie schafft die Grundlage, fundierte Entscheidungen über den Einsatz von KI zu treffen, indem Risiken transparent gemacht und die Vertrauenswürdigkeit eines Systems nachvollziehbar und prüfbar belegt wird.
Im Fokus steht dabei nicht allein das Modell, sondern das tatsächliche Verhalten der KI im Zusammenspiel mit Daten, Prozessen, Menschen und Organisation. Wir bewerten KI-Systeme konsequent im konkreten Einsatzkontext und führen technische Prüfung, organisatorische Einbettung sowie regulatorische Anforderungen zu einer integrierten Gesamtbewertung zusammen.
Worauf es bei vertrauenswürdiger KI ankommt

Safety & Security

Robustheit & Zuverlässigkeit
Nachvollziehbarkeit & Transparenz

Rechtskonformität & Standardisierung

Ethik & Governance
Wie wir AI Assurance konkret umsetzen
AI Assurance ist kein einmaliger Test, sondern ein strukturierter, lebenszyklusorientierter Prozess. Ziel ist es, Risiken frühzeitig zu erkennen, klare Anforderungen zu definieren und die Vertrauenswürdigkeit eines KI-Systems systematisch nachzuweisen.
Unser Vorgehen umfasst fünf zentrale Schritte:
Kontext & Risikoanalyse
Wir analysieren Einsatzkontext, Risiken und relevante Rahmenbedingungen, einschließlich regulatorischer Anforderungen, Standards und domänenspezifischer Vorgaben. Diese werden zu einem konsistenten Anforderungskatalog zusammengeführt.
Ihr Nutzen:
- Transparenz über reale Einsatzbedingungen
- Frühe Identifikation kritischer Risiken
- Klare Ausgangsbasis für fundierte Entscheidungen
Ableiten von Anforderungen
Auf Basis des Kontextes definieren wir konkrete, überprüfbare Anforderungen, einschließlich Metriken, Grenzwerte und Freigabekriterien. Diese werden so operationalisiert, dass sie sowohl technisch prüfbar als auch organisatorisch anwendbar sind.
Ihr Nutzen:- Klare Kriterien statt abstrakter Prinzipien
- Nachvollziehbare Entscheidungsgrundlagen
- Struktur für die Entwicklung, Bewertung und Freigabe
Technische Prüfung
KI-Systeme werden systematisch geprüft – von Simulationen über kontrollierte Testumgebungen bis hin zu realitätsnahen Einsatzszenarien. Dabei analysieren wir gezielt auch seltene und kritische Situationen sowie das Verhalten des Systems unter Unsicherheit.
Ihr Nutzen:
- Belastbare Aussagen zur Robustheit und Leistungsgrenzen
- Frühes Erkennen von Schwachstellen und Risiken
- Prüf- und auditierbare Nachweise
Assurance Dokumentation & Freigabebegleitung
Alle Ergebnisse werden strukturiert aufbereitet und in auditfähige Nachweise überführt. Gleichzeitig begleiten wir Freigabe- und Abstimmungsprozesse mit internen und externen Stakeholdern.
Je nach Ergebnis entstehen:- Freigaben
- Freigaben unter Auflagen
- Konkrete Maßnahmenpläne zur Risikoreduktion
Ihr Nutzen:
- Sicherheit in Audit- und Zulassungsprozessen
- Klare Kommunikation gegenüber Entscheidern und Prüfern
- Reduktion von Nacharbeits- und Abstimmungsaufwand
Betrieb, Monitoring & Weiterentwicklung
AI Assurance endet nicht mit der ersten Bewertung, auch nach der Freigabe bleibt das System im Fokus: Wir überwachen Verhalten, erkennen Veränderungen und führen gezielte Re-Evaluierungen durch. So stellen wir sicher, dass Ihre KI-Systeme auch langfristig zuverlässig, nachvollziehbar und verantwortbar im Einsatz bleiben.
Ihr Nutzen:
- Langfristig stabiler und kontrollierter Betrieb
- Früherkennung von Problemen im laufenden Einsatz
- Nachhaltige Sicherstellung der Vertrauenswürdigkeit
KI im Kontext komplexer Gesamtsysteme
KI-Systeme werden häufig als Bestandteil komplexer cyber-physischer und mechatronischer Systeme eingesetzt. Deshalb betrachten wir AI Assurance nicht isoliert, sondern immer im Zusammenspiel mit Sensorik, Software, Hardware, Menschen und operativen Prozessen.
Ihr Mehrwert
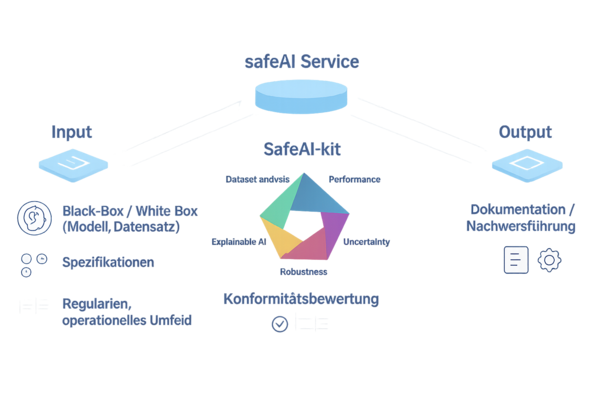
safeAI-Kit: Unser Werkzeugkasten für sichere KI
Das safeAI-Kit kombiniert standardisierte Methoden, etablierte Best Practices und eigene Ansätze, um zentrale Eigenschaften wie Robustheit, Unsicherheit, Erklärbarkeit und Systemgrenzen systematisch zu bewerten. Unsere methodische Arbeit basiert dabei nicht nur auf praktischer Erfahrung, sondern auch auf aktiver Mitgestaltung von Standards und Richtlinien. So entstehen belastbare und nachvollziehbare Nachweise, die sowohl technisch fundiert als auch für Entscheidungen und Audits nutzbar sind.
Was bedeutet das konkret für Sie?
- Konsistente und nachvollziehbare Bewertungen
Durch standardisierte und wiederverwendbare Prüfbausteine werden Ergebnisse vergleichbar und transparent. - Belastbare Aussagen statt punktueller Tests
Die Kombination verschiedener Methoden ermöglicht eine fundierte Bewertung des tatsächlichen Systemverhaltens – über isolierte Einzelprüfungen hinaus. - Effiziente Umsetzung von AI Assurance
Modulare Bausteine reduzieren den Aufwand und ermöglichen eine strukturierte, skalierbare Durchführung von Prüf- und Bewertungsprozessen. - Unterstützung über den gesamten Lebenszyklus
Das safeAI-Kit unterstützt nicht nur die initiale Bewertung, sondern auch Monitoring, Drift-Erkennung und kontinuierliche Re-Evaluierung im Betrieb.
Unsere Expertise in Standardisierung und Regulierung
Wir verbinden aktuelle Erkenntnisse aus KI-Forschung, Standardisierung und Regulierung mit langjähriger Erfahrung in Test-, Analyse- und Zertifizierungsprozessen.
Durch unsere aktive Beteiligung in nationalen, europäischen und internationalen Standardisierungsgremien tragen wir zur Weiterentwicklung von Anforderungen und Bewertungsansätzen für KI-Systeme bei.
Mit der Initiierung der DIN SPEC 92005 zur “KI-Quantifizierung von Unsicherheiten im maschinellen Lernen” leisten wir hierzu einen konkreten Beitrag. Dies diente als Grundlage für ein Standardisierungsprojekt bei ISO/IEC zum Thema Unsicherheiten in KI-Systemen, der ISO/IEC TS 25223. Dieser Standard wird bis voraussichtlich Anfang 2028 unter der Leitung der IABG entwickelt. Hier ein interessantes Interview mit unserem Normungsexperten Dr. Lukas Höhndorf “Normung macht den AI Act greifbar” (11.12.2025), durchgeführt vom DIN e.V..
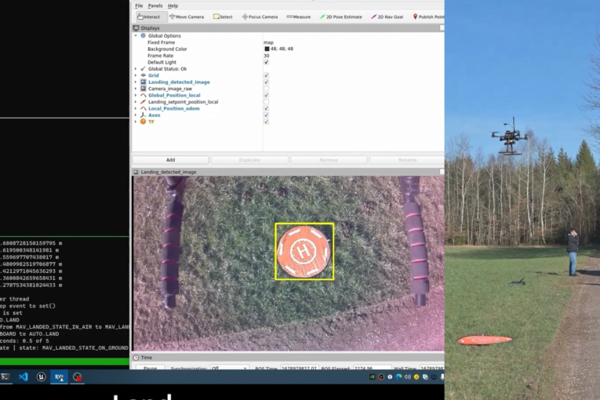

KI-Systeme.



AI Assurance: Vertrauen, Sicherheit und schnelle Einsatzfähigkeit für KI-Systeme in der Bundeswehr.
IABG-Beitrag AFCEA 2025
DownloadWie können wir Ihnen helfen?
Bitte füllen Sie das Formular aus, wir setzen uns umgehend mit Ihnen in Verbindung.
An dieser Stelle finden Sie Inhalte eines Drittanbieters, die Sie mit einem Klick anzeigen lassen können.
Mit dem Laden des Formulars können personenbezogene Daten an den Drittanbieter übermittelt werden. Mehr Informationen finden Sie in unseren Datenschutzbestimmungen.